This is a guest article from Yannie.
Hello everyone, this week we are going to learn something a little different, about the distributed consensus algorithm Raft. I’ll first explain to you what Raft is and why we need it. Then, I will introduce one of the fundamental concepts of Raft: leader election. Finally, I will introduce some issues that may arise during the implementation of the leader election. So let’s get started~
What Raft Is and Why We Need It
Let’s imagine that you have some data that you want to keep permanently and reliably. The simplest and most reliable approach is to make multiple copies of this data. In a distributed system, these copies are stored on different machines, which are typically geographically dispersed for fault tolerance. Therefore, during their communication, a series of problems such as machine crashes and network failures often occur. Ensuring the consistency of each copy is the most important concern in distributed systems.
In distributed systems, Replicated state machines (Details in Appendices A.1.) are used to solve a variety of fault tolerance problems in distributed systems. Replicated state machines are typically implemented using a replicated log, as shown in Figure 1.
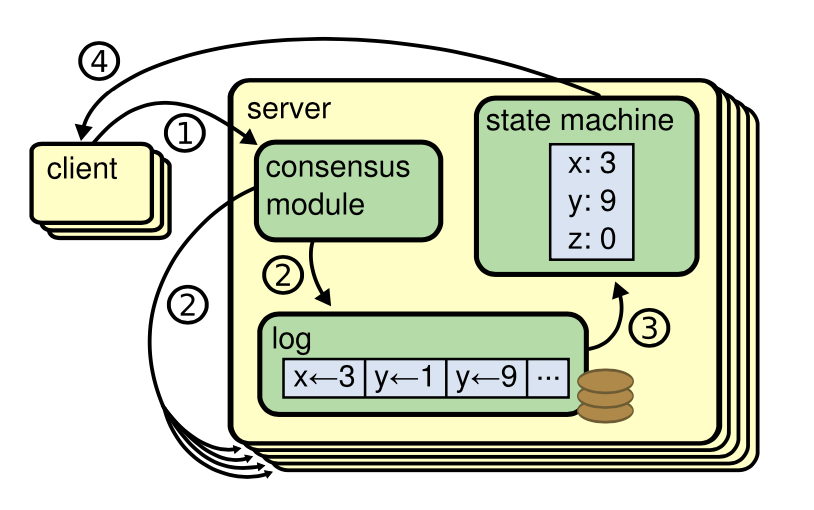
Each server stores a log containing a series of commands, which its state machine executes in order. Each log contains the same commands in the same order, so each state machine processes the same sequence of commands. Since the state machines are deterministic, each computes the same state and the same sequence of outputs.
Keeping the replicated log consistent is the job of the consensus algorithm. Raft is a consensus algorithm for managing a replicated log. It divided problems into three pieces: leader election, log replication, and safety, then that could be solved, explained, and understood relatively independently. As shown in Figure 2.

As a library, Raft ensures the state of key-value pairs in a KV server. When a command is received from a client, the server passes it to Raft, which then performs a series of local processing and broadcasts the operation received from the client to other replicated machines. Once these servers achieve consensus by Raft, the result is returned to the KV server and then to the client. As we don’t want the clients to feel like they are working with a group of replicated machines, the distributed consensus system needs to function like communicating with a single server.
So how does Raft ensure that the entire distributed system works like a single machine? And how can Raft ensure that the services in the system reach consensus on shared state in the face of any failures? Today, I will explain the leader election, one of the three important concepts in Raft.
Leader Election
In traditional fault-tolerance systems such as MapReduce, replication is determined by a single master, and GFS relies on a single server to select the primary server. However, the disadvantage of using a single entity to determine the primary is that it can encounter a single point of failure.
Therefore, we consider using the election mechanism to select a primary. However, traditional test-and-set servers cannot solve the problem of split brain(Details in Appendices A.3.). Split brain can lead to data inconsistency among different servers, so we need to be particularly careful in electing a primary. In distributed systems, a common approach is “majority wins.” Raft also relies on the property that “at least one server in the two largest sets of servers during two consecutive terms is common” to avoid split brain. In such a distributed system, it is also known as a Quorum system, where 2f+1 servers can tolerate f failures. Now, let’s take a closer look at the leader election in Raft.
Raft Basics
In raft, The servers are divided into three states: follower, candidate, and leader. The transition between these states is shown in Figure 3.
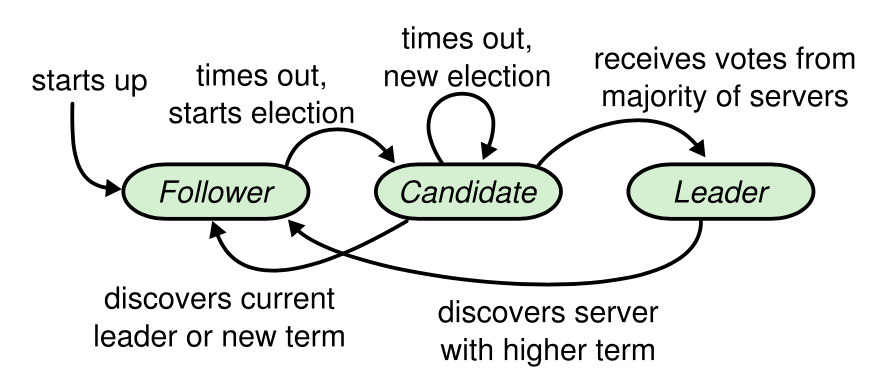
A Follower only responds to requests from the Leader and Candidate, and doesn’t send requests on its own. The Leader manages all client requests, while the Candidate is used to elect a new Leader.
For the leader, it regularly sends heartbeats to followers and candidates to let them know that there is already a leader in the system, thereby maintaining its authority. As for followers and candidates, they have an election timeout. Once the set election timeout is exceeded, they will initiate a new round of elections.
Term
Raft divides time into terms of arbitrary length, as shown in the Figure 4.
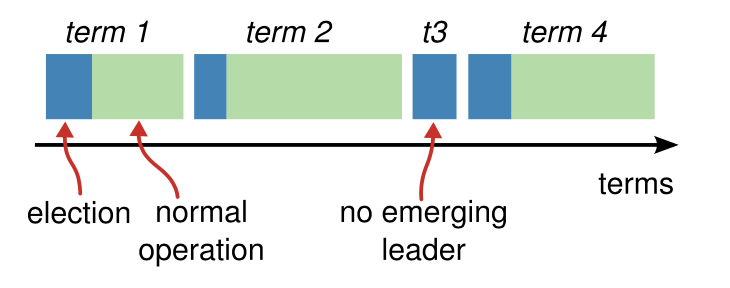
Terms are numbered with consecutive integers. The beginning of each term is marked by an election. If a candidate wins enough votes, it becomes the leader and takes over the term. If the vote is split and no leader is elected, the term ends prematurely. Raft ensures that at most one leader exists for a given term.
Benefits of Introducing Term
- term + index can uniquely identify a log entry.
- Terms act as a logical clock in Raft, allowing servers to detect outdated information. This can solve the problem of network delays. When a leader or candidate receives a larger term, it will become a follower.
Before formally introducing Raft election, let’s think about the following questions:
- Q1: How is the leader selected?
- Q2: What if the leader/follower/candidate is down? Can we still guarantee a unique leader?
- Q3: How to avoid two candidates becoming leaders at the same term?
- Q4: How to prevent one voter from voting multiple times in one term?
- Q5: What if a candidate fails to receive a majority of votes for a long time?
- Q6: How to ensure that a unique leader can be elected even in the case of network problems or server failures?
- Q7: How long after the vote is the next election? Why is it designed this way? Can we wait until a machine is down before changing the leader?
Election Procedure
After the election timeout of a follower expires, it will initiate a leader election.
-
At the beginning of the election, since each term can only have one leader, the candidate needs to increment its term number to indicate the start of a new election. Then, it changes its state from follower to candidate and votes for itself.
-
Parallel RequestVote RPCs are sent to every server in the cluster requesting their vote, and the candidate waits for their responses.
-
When a candidate receives a majority of votes, it becomes the new leader and immediately sends heartbeats to all servers in the cluster in parallel. If it does not receive a majority of votes, it updates its term and becomes a follower. If an election timeout occurs, a new round of elections will begin.
RequestVote Definition
type RequestVoteArgs struct {
Term int
CandidateId int
LastLogIndex int
LastLogTerm int
}
type RequestVoteReply struct {
Term int
VoteGranted bool
}
Let’s think about how to vote for a server in Raft:
- First, check if it is not a stale leader.
- Second, make sure that you have not voted for any other candidate
in the current term.
For the first condition, since we divide time into terms, we compare the term in the RequestVote RPC to determine if the leader is stale.
args.Term < rf.Term
return false
For the second condition, we just need to check if args.CandidateId has already voted for other servers. Additionally, we need to reset rf.voteFor to -1 when judging args.Term < rf.Term, because that is the vote cast for other servers in the expired term. Since each server can vote for only one candidate in a term, but can vote for different candidates in different terms, we need to clear the voting information when we discover the expired leader.
In addition, at the beginning, if multiple followers time out simultaneously, it will cause a tie, and there will be no leader, which will reduce the liveliness of the system. There are two methods to solve this problem: 1. ranking method 2. random timeout method.
Based on the rank method, the following problems may arise: a lower-ranked server might need to time out and become a candidate again if a higher-ranked server fails, but if it does so too soon, it can reset progress towards electing a leader
Random Timeout Method
- Raft uses randomized election timeouts to ensure that split votes are rare and that they are resolved quickly.
- To prevent split votes in the first place, election timeouts are chosen randomly from a fixed interval (e.g., 150–300 ms)
- Each candidate restarts its randomized election timeout at the start of an election, and it waits for that timeout to elapse before starting the next election;
Practical Problem
Livelocks
When the system enters the livelock state, all nodes of the entire system are performing certain operations, but because the nodes are in a certain state, the entire system cannot make progress.
One scenario: A leader cannot be elected, or once a leader is elected, a node initiates a new election, forcing the most recently elected leader to step down immediately.
Most of this is because your election timer is reset incorrectly,you should only restart your election timer if a) you get an AppendEntries RPC from the current leader (i.e., if the term in the AppendEntries arguments is outdated, you should not reset your timer); b) you are starting an election; or c) you grant a vote to another peer.
Appendices
A. Distributed systems
A.1. Replicated state machines
In computer science, state machine replication(SMR) is a general method for implementing a fault-tolerant service by replicating servers and coordinating client interactions with server replicas.
One characteristic of a state machine: If two state machines start in the same initial state and receive the same sequence of commands, they will end up in the same final state.
Based on the characteristics of state machines, to ensure that the final state of multiple machines is consistent, it is only necessary to ensure that their initial states are consistent and that the received operation instruction sequences are consistent, regardless of whether the operation instruction is to add, modify, delete or any other possible program behavior. This can be understood as broadcasting a series of operation logs correctly to each distributed server. During the broadcasting of instructions and their execution, the internal states of the system may be inconsistent, but it is not required that each instruction of all servers begins and ends synchronously. It is only required that the internal states can’t be observed externally during this period, and when the operation instruction sequence is completed, the final state of all servers is consistent. This model is called state machine replication.
A.2. Quorum mechanism
Considering that network partitioning in a distributed environment is an unavoidable phenomenon, and even allows for the system to no longer pursue the data states of all servers in the system being consistent under any circumstances, but instead adopts the principle of “the majority rules”. Once more than half of the servers in the system complete the state transition, it is considered that the data changes have been correctly stored in the system. This can tolerate a minority of servers being disconnected, making it beneficial to increase the number of machines for the overall availability of the system. This idea is called the “Quorum mechanism” in distributed systems.
A.3. Split Brain
Split Brain refers to a situation in a distributed system where different parts of the system are unable to communicate with each other due to communication failure or other reasons, resulting in a split state of the system into multiple independent subsystems. Each subsystem considers itself as the only legitimate part of the system. In the case of Split Brain, different subsystems may experience problems such as data conflicts, resource contention, etc., which may lead to system inconsistency and ultimately disrupt the correctness and availability of the system.
References
- State machine replication Wikipedia
- In Search of an Understandable Consensus Algorithm
- Student’s Guide
Comments