ReSTIR is an importance sampling method, which is so powerful you can render the whole scene realisitcally with just 1 sample per pixel (1spp). The original paper is available here. Before we begin, let’s take a look at its impressive result.

There are a few pieces of prerequisite knowledge, but worry not! We will go over it bit by bit. So let’s go!
Monte Carlo Estimator
To solve the Rendering Equation, we can (and have to) use the Monte Carlo estimator. It turns any form of integration from
\[I = \int f(x) dx\]into
\[\hat{I} = \frac{1}{N}\sum_{i=1}^N f(x_i)\]However, we can’t really just use that; poor, uniform sampled random variable \(x_i\) means a poor integration result. Especially when we need to solve the equation in real time , requiring high computational power, we want those samples to count.
Importance Sampling
Let’s take a look at importance sampling. It’s just a slight variation of the Monte Carlo estimator, allowing us to generate samples from non-uniform PDFs, while maintaining an unbiased result:
\[\hat{I} = \frac{1}{N} \sum_{i=1}^N \frac{f(x_i)}{p(x_i)}\]Now we can generate samples from a PDF that (probably) aligns better with the Rendering Equation distribution. The better they are aligned, the less samples we need to take to achieve an accurate estimate, with the extreme case being one sample. Let’s take a look at why.
If we want to integrate, say, \(\int_0^\pi sin(x) dx\). We pick a PDF that is a normalized version of the function, \(p(x) = \frac{sin(x)}{2}\). Now we generate a sample from this using inversion sampling, which looks like this:
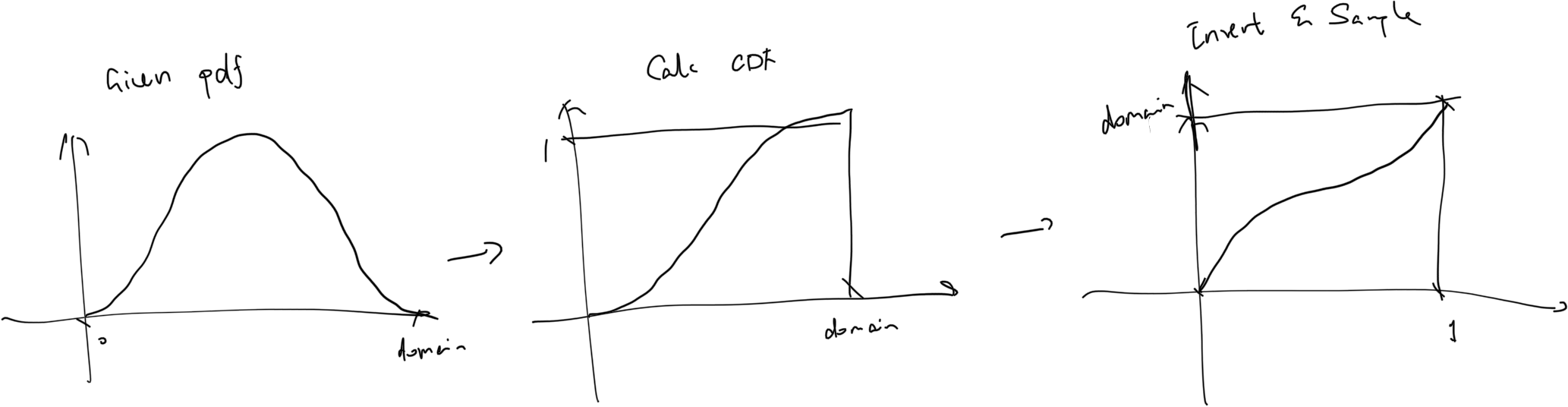
So now some random sample has been generated, say, \(\frac{\pi}{2}\). Plugging it into our importance sampling estimator, we get
\[\begin{align} \hat{I} &= \frac{1}{1} \sum_{i=1}^1 \frac{f(x_i)}{p(x_i)} \\ &= \frac{\sin(\frac{\pi}{2})}{\frac{1}{2}\sin(\frac{\pi}{2})} \\ &= 2 \end{align}\]Wow. So, the better the PDF aligns with target distribution, the better the integration result with fewer samples. And why is that? Because explained in simple terms, to normalize the distribution, we have to divide the whole function with its integration result.
Multiple Importance Sampling (MIS)
Multiple Importance Sampling is a sampling technique from Veach’s thesis. I haven’t read it myself, but I heard it’s really good.
Imagine we are rendering a scene. Now, although importance-sampling the from light direction or the BRDF can both result in a better integration result, it’s not always the best; if we are shading a diffuse surface and there are two light sources, one big and one small, neither directly sampling from the light direction nor sampling from the BRDF can result in the best performance & accuracy. Ideally the best result would be sampling their combined PDF, but it’s just infeasible to get the PDF for both light direction & BRDF (since getting the precise PDF requires integrating the Rendering Equation, which is a chicken & egg problem.) What should we do?
Introducing the Multiple Importance Sampling (MIS), which tries to tackle this problem:
- Take M PDFs
- Draw N sample points from each PDF
- Perform mini Monte-Carlo integration for each PDF, except:
- Weight each sample contribution by multiplying it with \(w_i(x_{ij})\)
For each mini Monte-Carlo integration, the weight needs to satisfy
\[\begin{cases} \sum_{i=1}^{M} w_i(x) = 1 \text{ whenever } f(x) \neq 0 \\ w_i(x) = 0 \text{ whenever } p_i(x) = 0 \end{cases}\]Translating that back into human language, that means
- The weighting functions among different PDFs should sum to one given a sample point;
- Weighting function for PDF i at point x should be 0 if the PDF i at point x is zero; this is used to prevent division by zero error.
Suppose we have three different PDFs and we one sample from each (\(x_{11}, x_{21}, \text{and } x_{31}\).) The estimator now looks like this:
\[\begin{align} \hat{I} &= \sum_{i=1}^3 \frac{1}{1} \sum_{j=1}^1 w_i(x_{ij}) \frac{f(x_{ij})}{p_i(x_{ij})} \\ &= w_1(x_{11}) \frac{f(x_{11})}{p_1(x_{11})} + w_2(x_{21}) \frac{f(x_{21})}{p_2(x_{21})} + w_3(x_{31}) \frac{f(x_{31})}{p_3(x_{31})} \end{align}\]If the weighting functions are constant over the whole domain, this becomes
\[\hat{I} = w_1 \frac{f(x_{11})}{p_1(x_{11})} + w_2 \frac{f(x_{21})}{p_2(x_{21})} + w_3 \frac{f(x_{31})}{p_3(x_{31})}\]Where \(w_1 + w_2 + w_3 = 1\). But this performs poorly when any of the given PDF is bad, because variance is additive, and any bad PDF among \(p_1, p_2, \text{and } p_3\) will result in a poor estimation.
And so, as a result, choosing a weight function is apparently very important. One of those is balance heuristic:
\[\hat{w}_i(x) = \frac{N_i p_i(x)}{\sum_{k=1}^M N_k p_k(x)}\]Plugging it back into the MIS equation yields
\[\begin{align} \hat{I} &= \sum_{i=1}^M \frac{1}{N_i} \sum_{j=1}^N \frac{N_i p_i(x_{ij})}{\sum_{k=1}^M N_k p_k(x_{ij})} \frac{f(x_{ij})}{p_i(x_{ij})} \\ &= \sum_{i=1}^M \sum_{j=1}^N \frac{f(x_{ij})}{\sum_{k=1}^M N_k p_k(x_{ij})} \end{align}\]Looking back at our previous example, if we use balance heuristic, it becomes
\[\begin{align} \hat{I} &= \frac{f(x_{11})}{\sum_{k=1}^M p_k(x_{11})} + \frac{f(x_{21})}{\sum_{k=1}^M p_k(x_{21})} + \frac{f(x_{31})}{\sum_{k=1}^M p_k(x_{31})} \\ &= \frac{f(x_{11})}{p_1(x_{11}) + p_2(x_{11}) + p_3(x_{11})} + \frac{f(x_{21})}{p_1(x_{21}) + p_2(x_{21}) + p_3(x_{21})} + \frac{f(x_{31})}{p_1(x_{31}) + p_2(x_{31}) + p_3(x_{31})} \end{align}\]If the first PDF aligns pretty well with f near the region of x, then the \(f(x)\) result will be big as well as \(p_1(x)\); as a result we will count towards its contribution more in this scenario.
Sampling Importance Resampling (SIR)
Sampling Importance Sampling (or Sequential Importance Resampling, also SIR) is a sampling technique that works like this:
- I have a target PDF \(\hat{p}(x)\) that is hard to draw samples from. (Inversion sampling is expensive sometimes.)
- I have a proposal PDF \(p(x)\), which looks a little bit like the target PDF, and drawing samples from that is cheap
- Draw M samples from the proposal PDF
- For each sample taken, assign weight to it: \(w(x_i) = \frac{\hat{p}(x_i)}{p(x_i)}\)
- Draw one (1) sample from the sample pool. Probability of a sample being drawn is proportional to its weight.
A few strong benefits can come from using SIR:
- We don’t need to know how the target PDF looks like, we just need to know how to evaluate it
- Add a constant scaling factor on target PDF and the result will remain the same
Point 2 is very useful since the target PDF doesn’t even need to be a PDF now. It might as well be any distribution, which, coincidentally, the Rendering Equation without the integration is a distirbution as well!
Remember the one-sample talk we had earlier? Now we don’t need to integrate the function in advance, because PDF is retrieved from normalizing the distribution, which means dividing the distribution by its integrated result over the whole domain. With SIR, we can now generate samples from all kinds of weird, unknown PDFs.
However, SIR is not the holy grail and its downsides are also pretty obvious:
- Not trackable, as in no closed-form SIR PDF.
- The first downside leads to the second; non-trackable PDF means we can’t use things like balance heuristic, since that requires evaluating the PDF of SIR
- Sometimes we need a lot of proposal samples to achieve a good approximation. And sometimes, proposal samples are not that cheap as well.
Resampled Importance Sampling (RIS)
Resampled Importance Sampling, proposed by Justin Talbot, opens up the possibility of exploting SIR to evaluate the integration result of the target PDF. Here’s how it works:
- Draw M samples from the proposal PDF \(p(x)\) with weights attached
- Draw N samples with replacement (so there can be duplicate samples) from the sample pool M
- Sum them up with a bias correction factor. The formula is given below.
The weights in bias correction factor for each sample point in SIR sample pool is
\[w(x_j) = \frac{\hat{p}(x_j)}{p(x_j) M}\]Let’s take a look at an example. Suppose we have a integrand that is basically impossible to know, say, \(f(x) = x^3 \sin(3x)\), and we want to integrate it from 0 to \(\frac{\pi}{2}\). Here’s what Wolfram Alpha says:
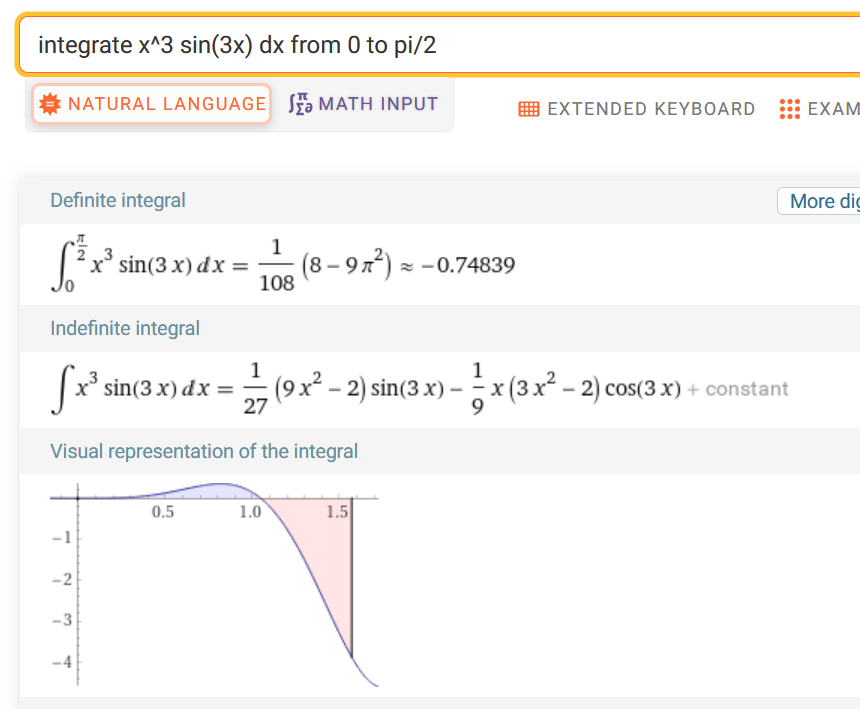
In practice, we don’t know what’s inside f(x), but we do have a vague idea of how it might look like, since it should at least kind of resemble \(\hat{p}(x) = x^3\). This can be our target distribution. Although in our example, \(x^3\) is pretty easy to sample from, in reality, the target distribution sampling procedure can also be nontrivial: maybe it’s the combined light incoming directions, or something else. That’s when the proposal PDFs come in, which is quick and easy to sample, such as 1 direct light. Or in our case, \(p(x) = \sin(x)\).
Picking \(\sin(x)\) here is just for demostration purposes; I use the sine PDF to show that any PDF can be picked while using RIS. It’s just bad proposal PDF means more samples.
Anyway, here’s what we have so far:
- A function to integrate \(f(x) = x^3 \sin(3x)\)
- A target distribution, \(\hat{p}(x) = x^3\)
- A proposal PDF, \(p(x) = \sin(x)\)
Note that \(\int_0^{\frac{\pi}{2}} \hat{p}(x)\) doesn’t even equal to one. And here’s when RIS shows its magic:
- M SIR samples are taken using the inversion sampling method according to \(p(x)\), and each of them have a weight attached to them \(w(x_j) = \frac{\hat{p}(x_j)}{p(x_j) M}\)
- N RIS samples are taken from the SIR samples proportional to its weight
- Estimate the integration result \(\hat{I} = \frac{1}{N} \sum_{i=1}^N \frac{f(x_i)}{\hat{p}(x_i)} \sum_{j=1}^M w(x_j)\)
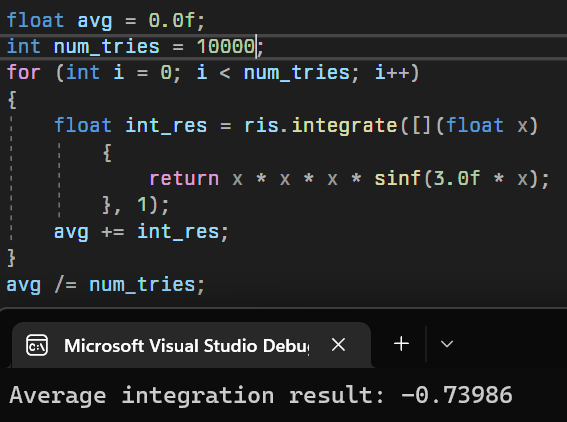
In our case, let’s set \(N = 1\) so we evaluate the RIS integration from a single sample. The result? Even though most of the time it got the answer wrong, we only ever need 1 sample (for RIS), and the integration is unbiased, and converges to our desired result:
In reality RIS is really just a special form of importance sampling, and as a result, can be used by MIS as part of its sampling strategies:
\[\hat{I} = \sum_{i=1}^M \frac{w^{\text{RIS}}}{N_i} \sum_{j=1}^N w_i^{\text{MIS}}(x_{ij}) \frac{f(x_{ij})}{\hat{p}_i(x_{ij})}\]Where \(w^{\text{RIS}}\) is the bias correction factor \(\sum_{j=1}^M w(x_j)\). Note that the M here means different things, in the MIS formula above the M means number of sampling strategies, and in the \(w^{\text{RIS}}\) it means number of samples drawn from the proposal PDF.

If the sketch above is too small on your screen, you can view it here.
It’s getting kind of crazy, but stay with me. Another way of combining RIS with MIS is that we can draw from multiple proposal PDFs forming the initial sample pool of M. We can then evaluate the integration result using RIS. One small modification is needed: we need to update the SIR weights to
\[w_i(x) = w_i^{\text{MIS}}(x) \frac{\hat{p}(x)}{p(x)}\]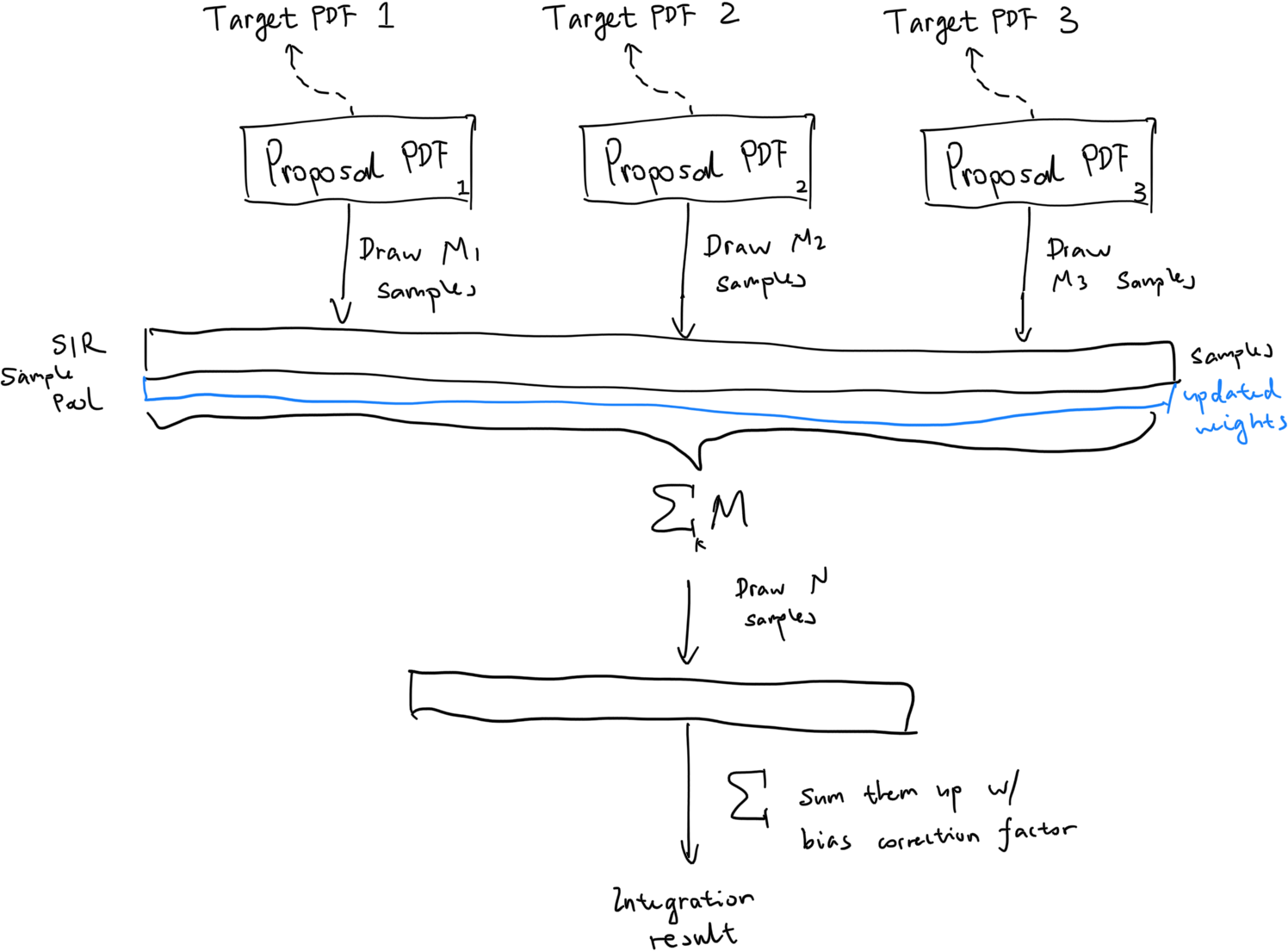
Here’s the original image.
Weighted Reservoir Sampling (WRS)
In the example presented above, even if the RIS has a sample size of \(N=1\), since we need to sample that from the SIR sample pool, we still need to store the whole SIR sample array, which has a storage size of M, so that’s not good. But do we really need that?
Here’s when the Weighted Reservoir Sampling (WRS) comes into play. It basically looks like this:
struct Reservoir
{
Sample picked;
float sum_weights;
};
//
// Update the reservoir;
// sum_weights will be updated to the total number of weights seen so far.
// If the randomly generated number is less than the normalized weight
// for current sample, then we pick the sample.
//
void update(Reservoir &r, Sample s)
{
r.sum_weights += s.weight;
if (random() < s.weight / r.sum_weights)
{
r.picked = s;
}
}
//
// Reservoir sample a stream of samples, for M times.
//
void reservoir_sampling(Reservoir &r, Stream<Sample> &s, int M)
{
for (int i = 0; i < M; i++)
{
r.update(s.next());
}
}
Now, this algorithm is very useful because it effectively reduces the storage requirement to \(O(1)\), because we no longer need an array to maintain the M samples we take using the SIR method anymore.
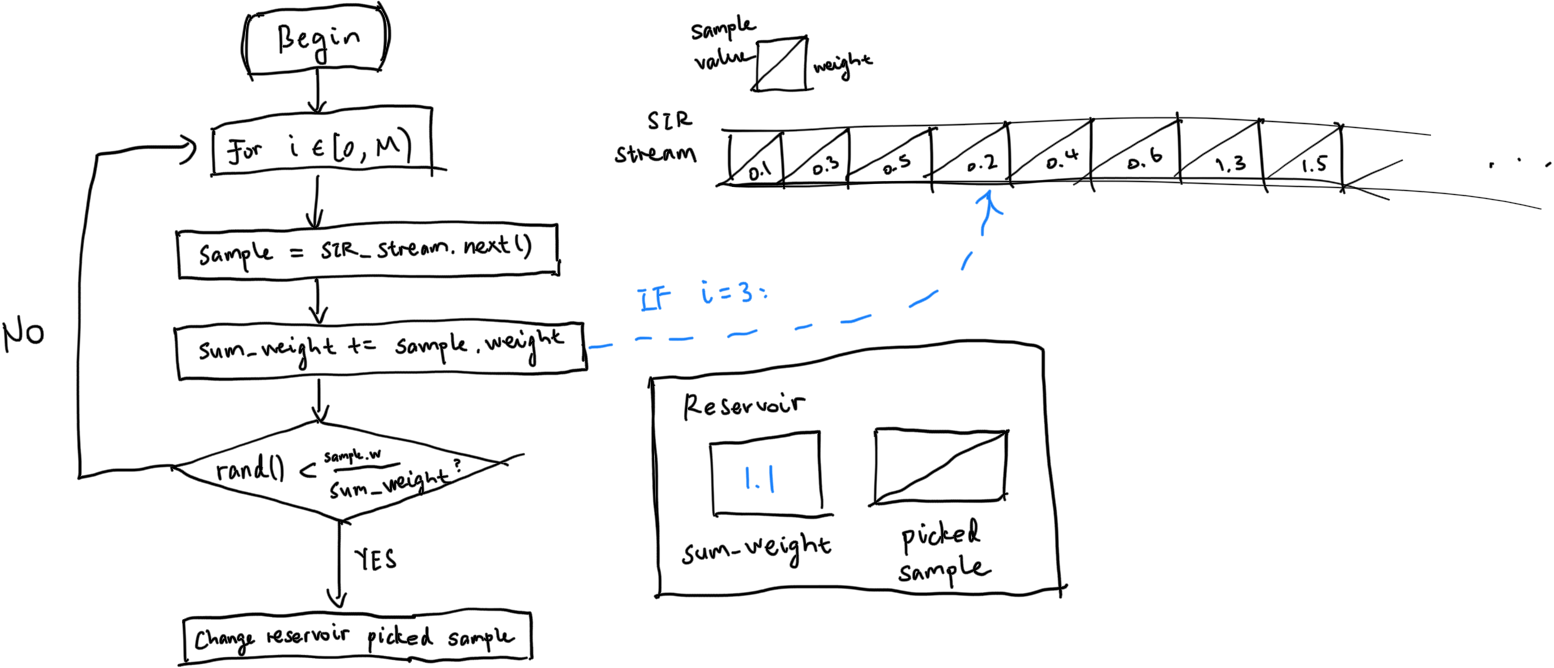
Naive ReSTIR DI
Finally, we have gathered all prerequisite knowledge for ReSTIR, short for Reservoir-based Spatio-Temporal Importance Resampling. The basic idea is just that - combining RIS with WRS:

According to the paper, it states “We generate samples uniformly over the area of emitters and use the unshadowed path contribution \(\hat{p}(x) = \rho(x) L_e(x) G(x)\) as the target distribution, only tracing shadow rays for the N surviving RIS samples.” In other words, the SIR sample stream generates samples over the hemisphere where direct lighting from emitters could hit sample point; then WRS is used to pick the One True Sample (or Multiple True Samples), and integration is done over it. Since we don’t need to trace shadow rays, the SIR samples are relatively cheap to come by, and there’s little to nothing to integrate. Therefore, the whole process is very quick, and the integrated result is kind of correct.

As we can see here, compared to Moreau et al.’s importance sampling algorithm, RIS with WRS can already render the subway scene either faster under the same quality, or, better quality in the same time.
ReSTIR DI then takes it one step further and states that obviously when two shading pixels are very close to each other, their lighting contributions must be very similar as well, so we can actually reuse that result. Here, ReSTIR exploits a very cool feature of WRS: the WRS procedure can be recursive. As in, we can do weighted reservoir sampling on reservoirs. Since reservoirs also hold a sample value and a weight, which is the requirement of a WRS sample, reservoirs themselves can act as a sample as well. So, by sampling neighbor’s reservoir and current shading pixel’s own reservoir, we may obtain a better result when the neighbor’s reservoir holds a better sample.
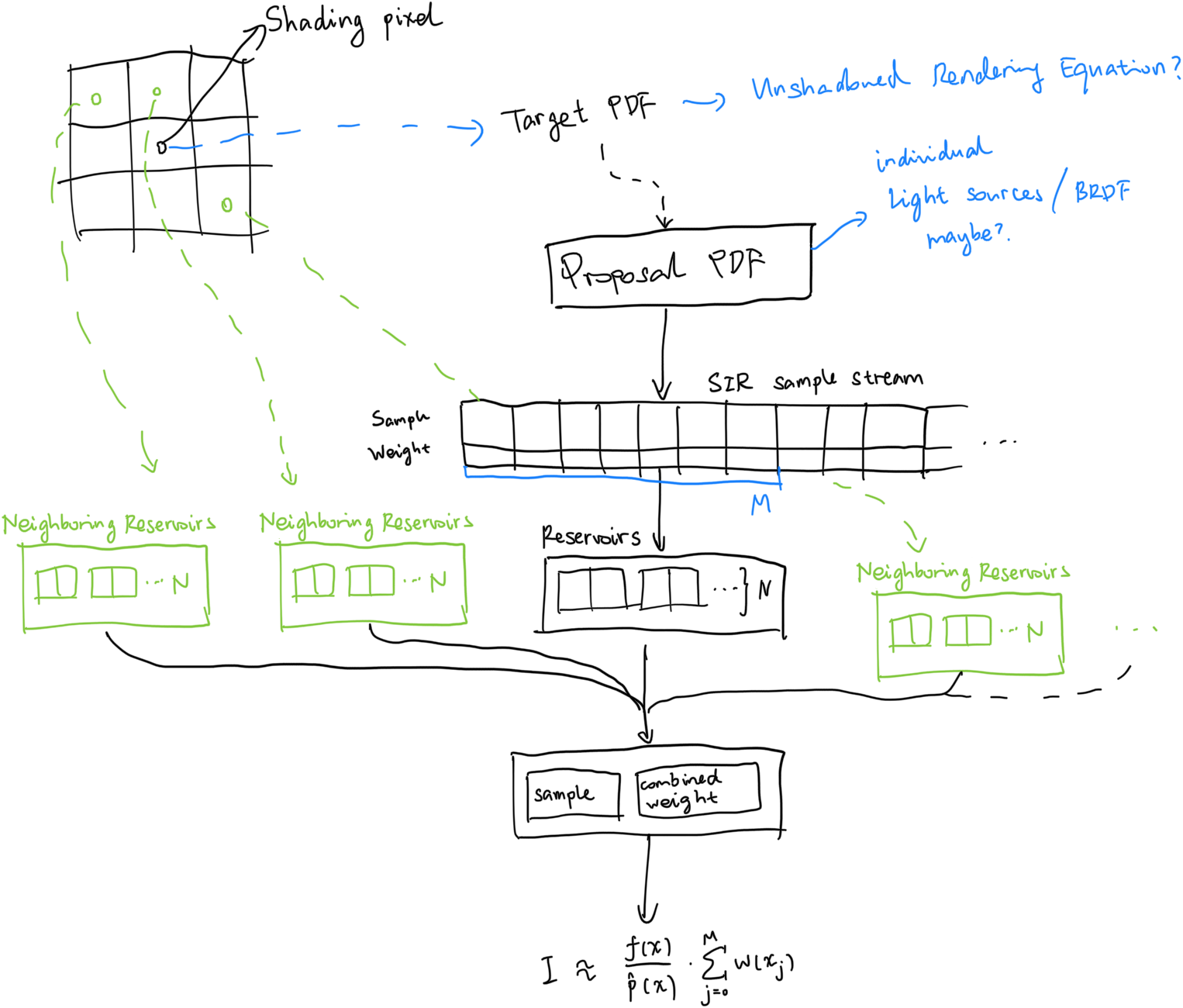
Because we are importance sampling the unshadowed Rendering Equation (with light emitters being proposal PDFs,) sometimes we may generate rays that hits an obstacle on the way to the light source. Those are bad samples, and we discard the reservoir here, so they do not partake in the spatial reusage.
If we are already reusing spatial neighbors anyway, why not take it one step further (again) and reuse temporal information as well? Like Temporal Anti-Aliasing (TAA)? So let’s do it! Let the prior frame be part of the contribution as well.
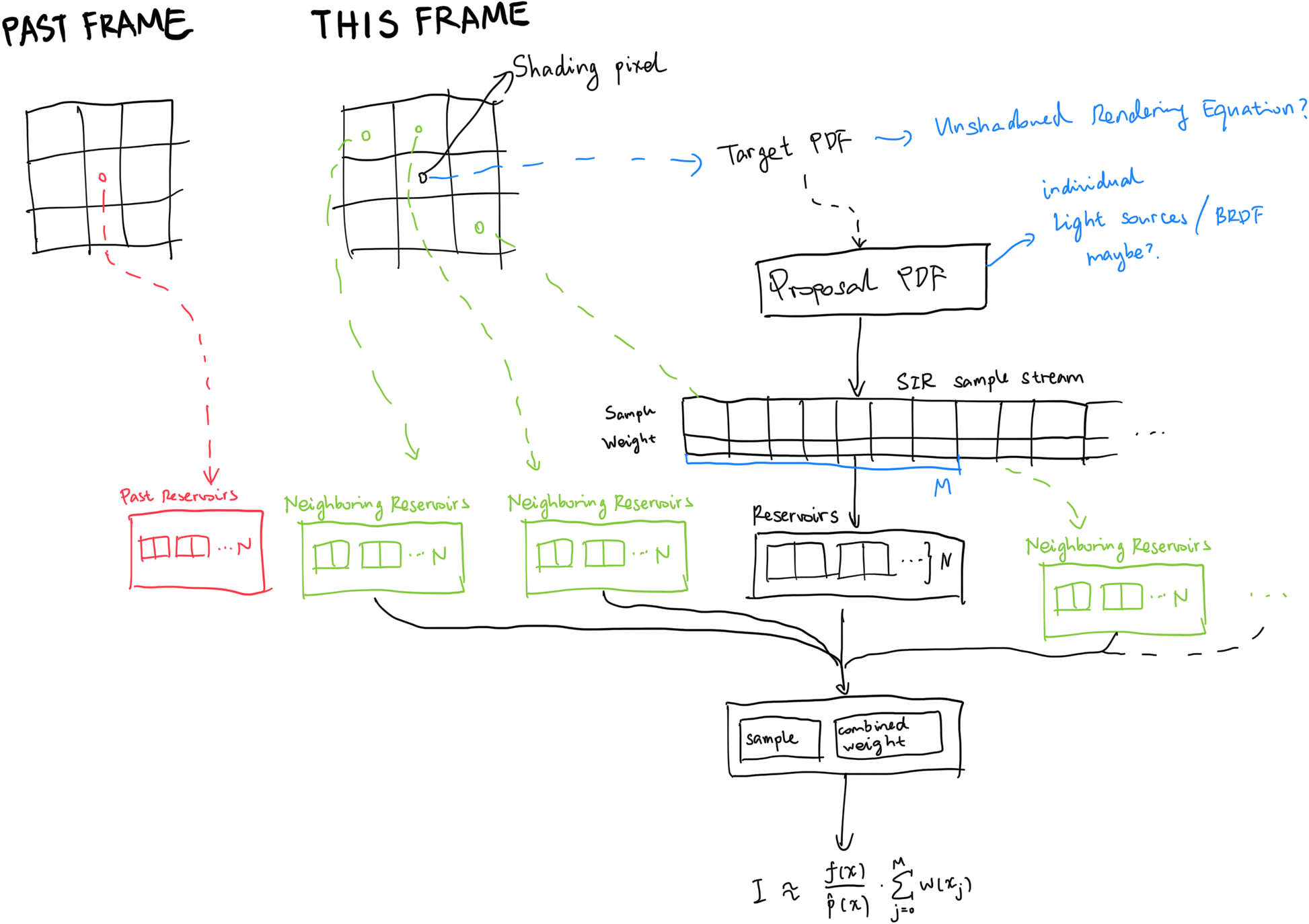
Obviously bad, occluded samples from the past frame need to be discarded as well.
Below is a comparison between with/without temporal reuse. As we can clearly see, the render has been greatly enhanced, with almost no extra computational cost.

So yeah, that’s ReSTIR DI, in a (very big) nutshell. The end. Thanks for reading. Bye!
Bias
Except it isn’t. Why? Because renders done in this way is actually biased; spatial & temporal reuse means samples are drawn from different pixels, but each pixel have a different integration domain, and reusing that may introduce bias. However, since we are just understanding the basics of ReSTIR here, it’s kinda out of the the scope of what we are discussing here today (I also maybe didn’t read that far.) If you are interested, you can check out some reference articles. All of them are of great help during my study.
References
- Understanding The Math Behind ReStir DI | A Graphics Guy’s Note: very very helpful article. Way more in depth than this one, so please check it out.
- Monte Carlo Integral with Multiple Importance Sampling | A Graphics Guy’s Note: an article that introduces MIS thoroughly.
- Chapter 9: Multiple Importance Sampling: chapter 9 of Veach’s thesis.
- Spatiotemporal reservoir resampling for real-time ray tracing with dynamic direct lighting: the original ReSTIR paper released by NVIDIA.
- ReSTIR GI: Path Resampling for Real-Time Path Tracing: a variant of ReSTIR.
- Generalized Resampled Importance Sampling: Foundations of ReSTIR (also known as ReSTIR PT): another variant of ReSTIR.
- Volumetric ReSTIR: yet another variant of ReSTIR.
- Importance Resampling for Global Illumination: the original RIS paper by Talbot.
Comments