Previous weeks:
- Week 1: project introduction and high-level design
- Week 2: model loading & intersection
- Week 3: rudimentary UI and job dispatch system
- Week 4 (you are here)
Hello September! This is week 4 of me trying to write a pathtracer in Lua (with no pathtracer… yet.) This week, we will build upon what we have achieved last week to make a fully functional multithreading model, so that things can actually speed up.
Job Queue
Although Lua has something called “coroutine”, they are merely lightweight threads, and does not actually run simultaenously. Therefore, coroutine does not exploit the benefit of having multiple CPUs, and is not suitable for our needs. What we need is real multithreading support.
There are some real multithreading libraries out there for Lua as well - effil being the most prominent one. However, writing one ourselves will always give us finer-grained control over it. So let’s write one!
Here’s the high-level design. When the application starts up, maximum amount of threads are started with it as well. Then, using a std::condition_variable, these worker threads start waiting for new jobs entering the job queue. Once a job enters the job queue, they start to work, and after that, they revert to being idle again.
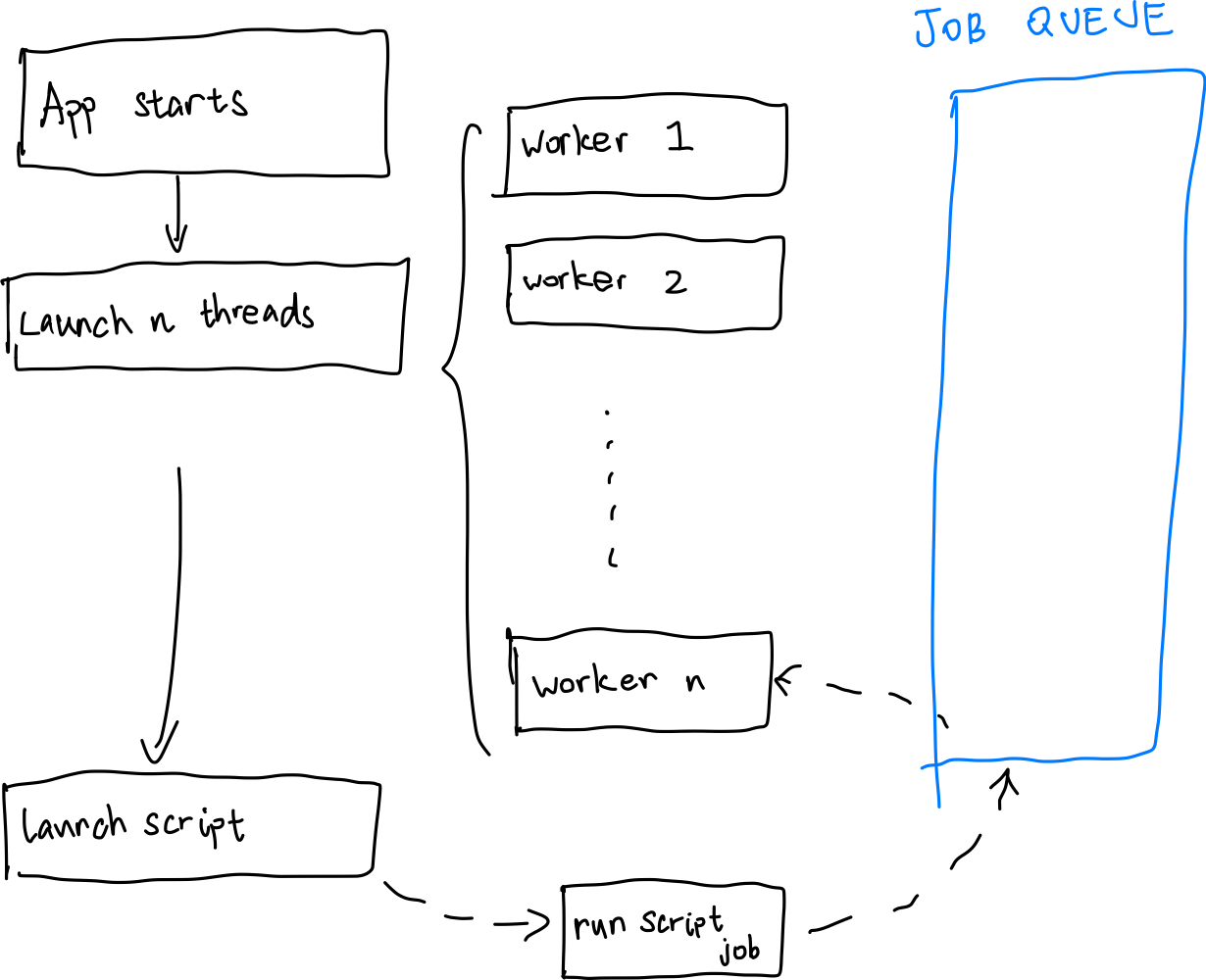
You can check out week 3 for an approximate implementation on the worker thread. Workers will execute corresponding work routine according to the job type passed along with the job description. They can either be do nothing, kill thyself, run a script, or execute parallel bytecode. We are going to take a gander at the last one.
Executing Bytecode
Inside our C++ implementation, we defined a function called shade, requiring the following parameters:
shade(int w, int h, int image_handle, function shade_function)
The image handle points to a Image implemented in C++. You can see its implementation in week 1. We register this function to our Lua state using the Lua C API. When the Lua script calls this function, \(w \times h\) parallel jobs are pushed into the job queue, with the following job description:
struct ParallelParams
{
float u, v;
int x, y, w, h;
std::string bytecode;
int image_handle;
};
Since the Lua state machine is very fragile when it comes to multithreading, and though lua_newthread does return a new lua_State *, that doesn’t support real multhreading environment in reality (trust me, I tried.) As a result we’ll have to create separate lua_State *s for each worker thread, isolating basically everything. This is also the solution of the effil library.
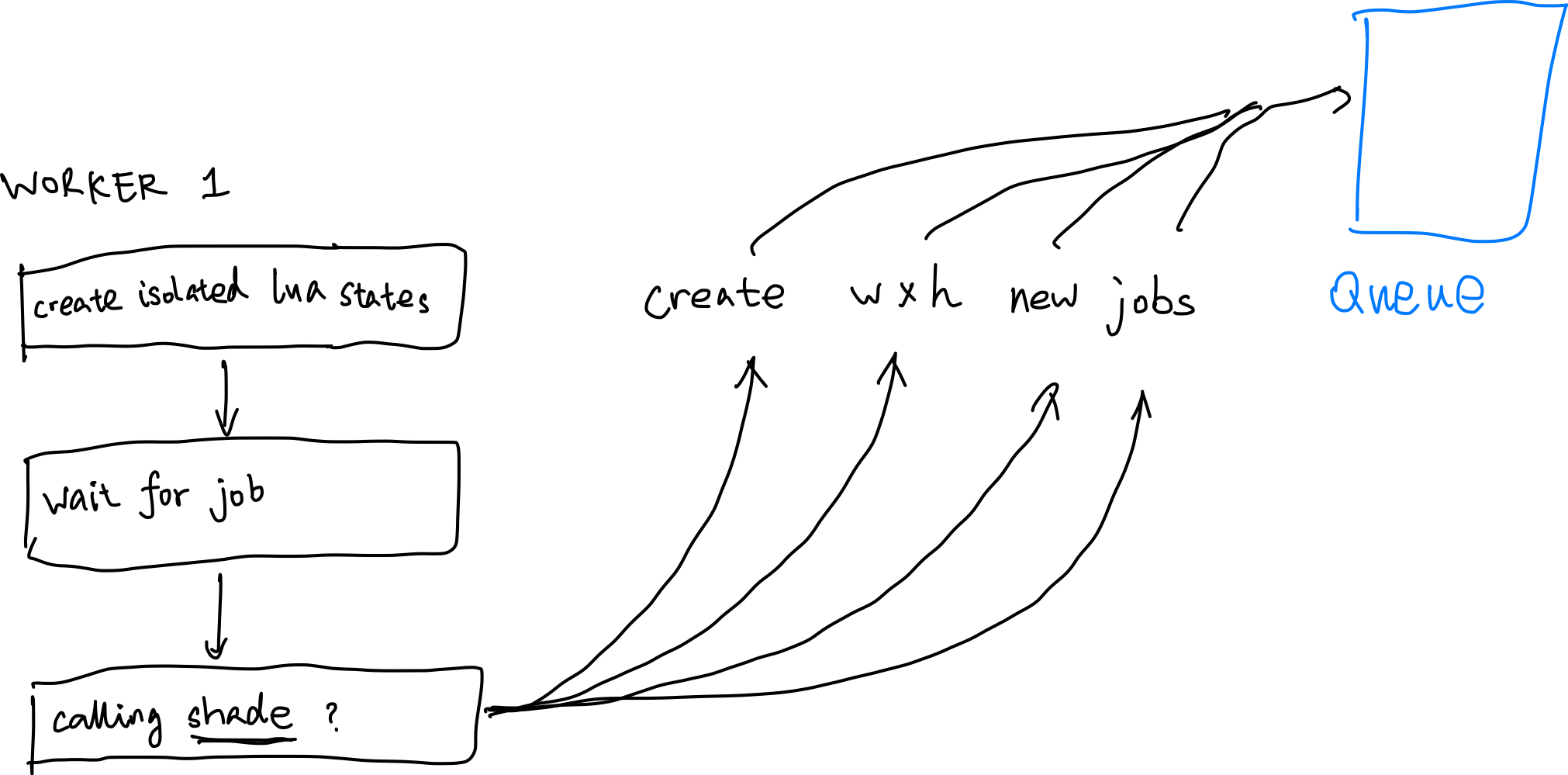
But when all Lua states are isolated, the problem now becomes - how do we pass the function defined in one Lua state to another Lua state? To that end, we make use of lua_dump to dump the whole function to a string (in the form of bytecode,) then each worker loads it back up and executes it.
void Lua::call_shade(const std::string &bytecode, float u, float v, int x, int y, int w, int h, int image_handle)
{
int error = luaL_loadbuffer(l, bytecode.c_str(), bytecode.size(), "shade");
if (error)
{
std::stringstream err;
err << "Failed to load bytecode: " << lua_tostring(l, -1);
err_log.push_back(err.str());
}
lua_pushnumber(l, u);
// push all 7 parameters...
if (lua_pcall(l, 7, 0, 0))
{
// pcall failed
}
}
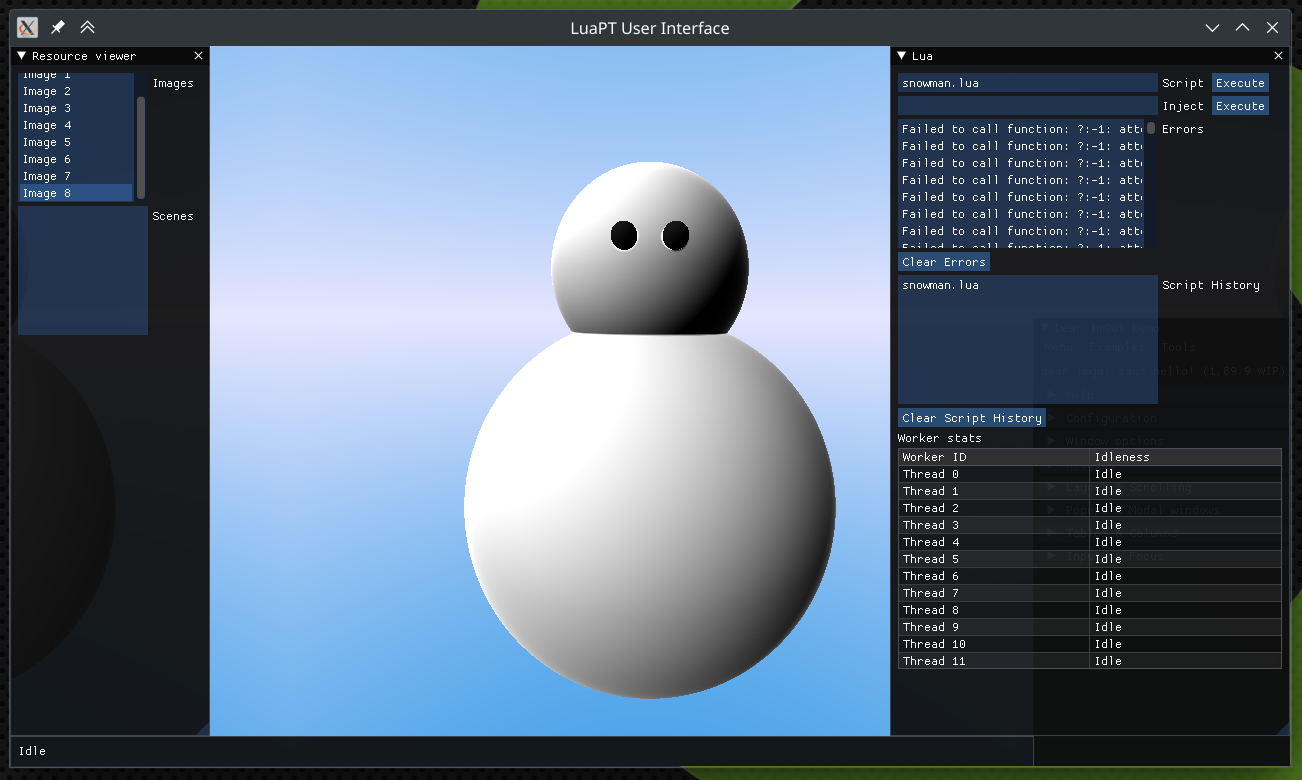
Current Result
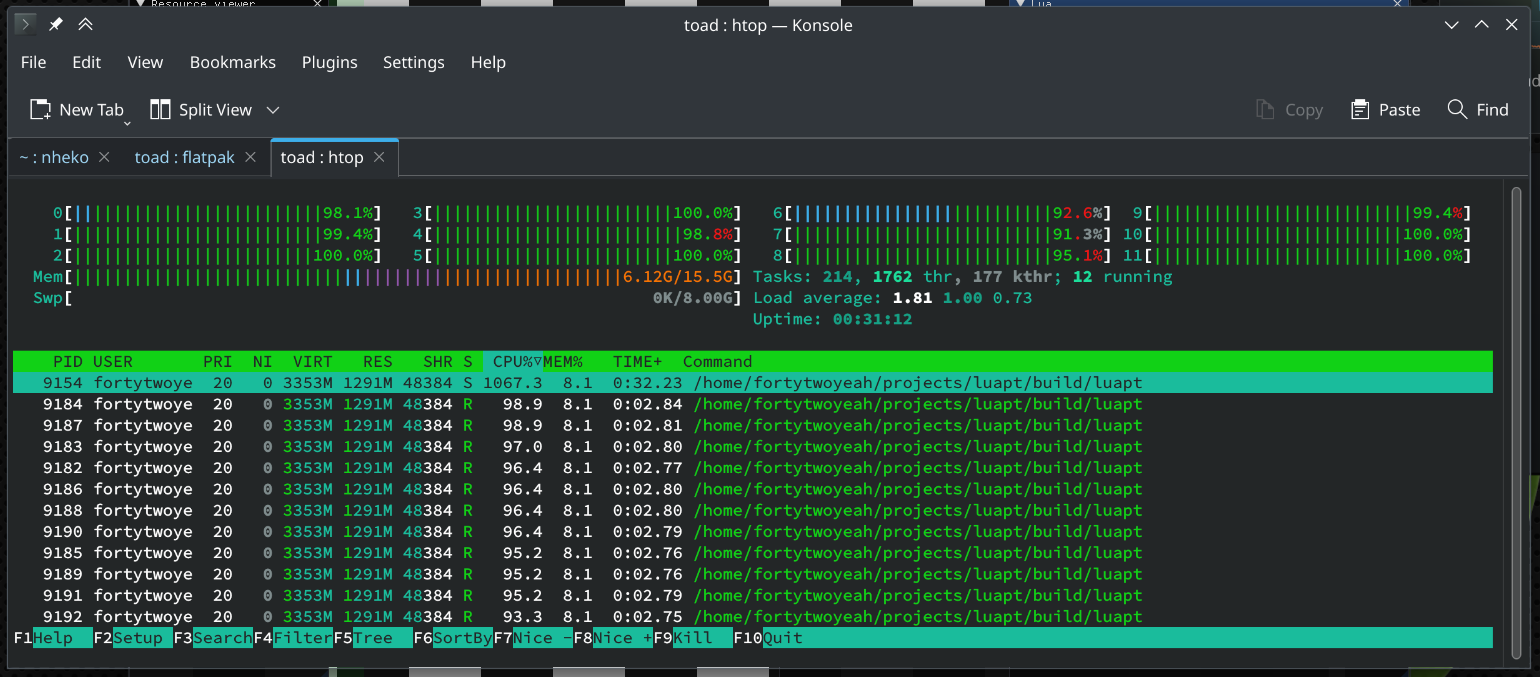
After adding some additional bells & whistles, we can now finally raymarch a 720x720 snowman in acceptable speed. It’s still slow. :(
(And yes, I forgot to close ImGui::ShowDemoWindow.)
Even though concurrency has been achieved, data transportation still poses a great challenge. Right now we hack this by setting the image handle directly as one of the many parameters of the shade user function; but in the future when there are meshes, scenes, and BVHs, we might not be as lucky. My one idea is to use shared tables for all and access can only be done via registered C functions (so not entirely in Lua.) Although it’s not as graceful, I suppose this will further accelerate the render speed so I might go on that path. As always, stay tuned for more!
Comments